SmartVision 2.7 - Release Description
Contents
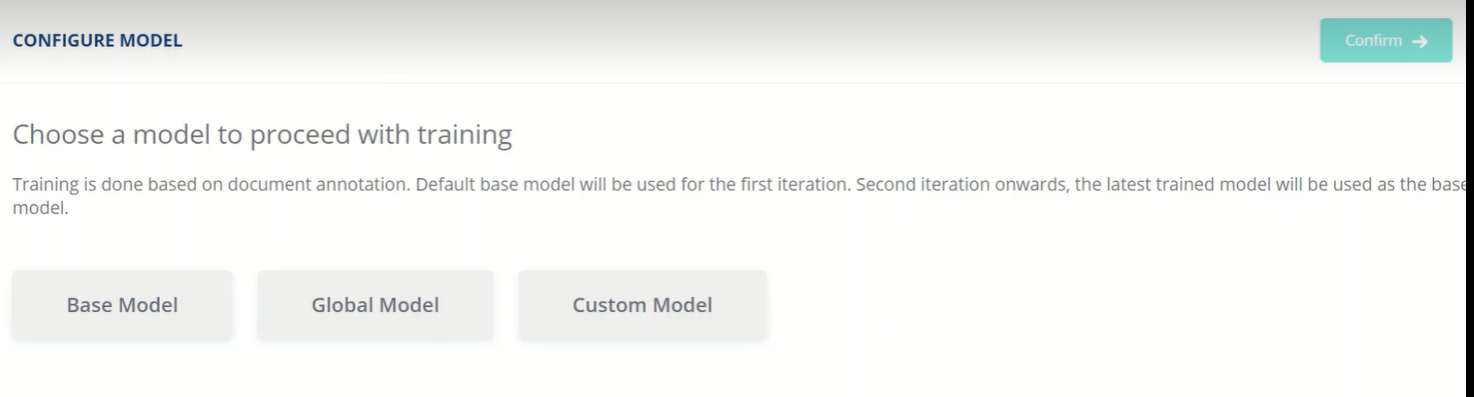
Extraction from QR Codes/ Barcodes
QR codes are available in almost all industry standard documents such as invoices, receipts etc. and so, extracting this information is crucial for document centric business processes. SmartVision has the capability to extract the information embedded in QR codes/ Bar codes and map it to the corresponding FOIs, thus eliminating the need for manual intervention by facilitating the automated decoding of QR Codes/ Barcodes.
As a prerequisite, you would need to configure the fields to be extracted as part of the Extraction FOI list.
The following screenshot displays a document from which information was extracted from Barcode available in the document.
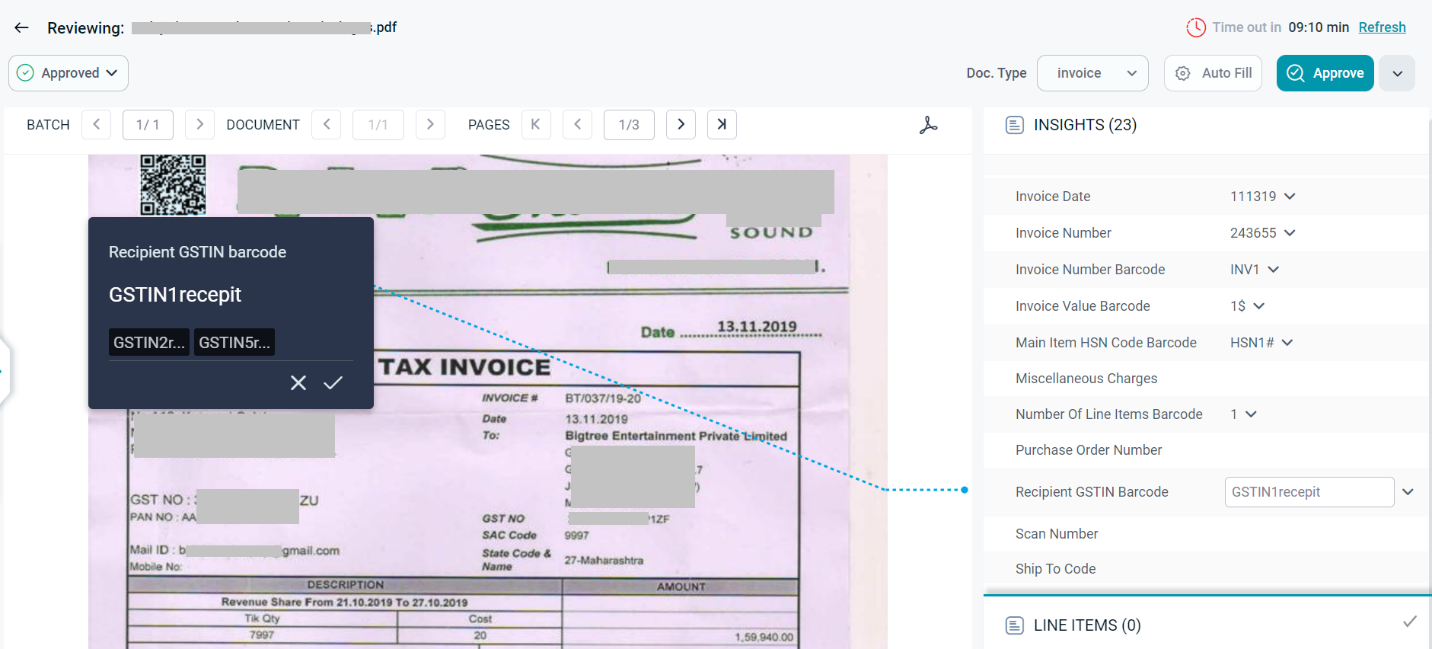
Extraction from Logos
Logo extraction plays an important role in information retrieval from logo based documents. Logos are generally graphic symbols or graphics and text indicating the organization/ vendor name and SmartVision has the capability to extract vendor name from the logo available in the document.
A supervisor or a reviewer can perform Logo Extraction on a document.
Ideally, the Logo in the imported document is first identified, the vendor name is extracted from it, and the extracted vendor name is mapped to the corresponding FOI.
To enable logo extraction, you can add custom field manually in your respective project in which you want to use the logo extractor.
The following screenshot displays a document from which information was extracted from organization logo available in the document.
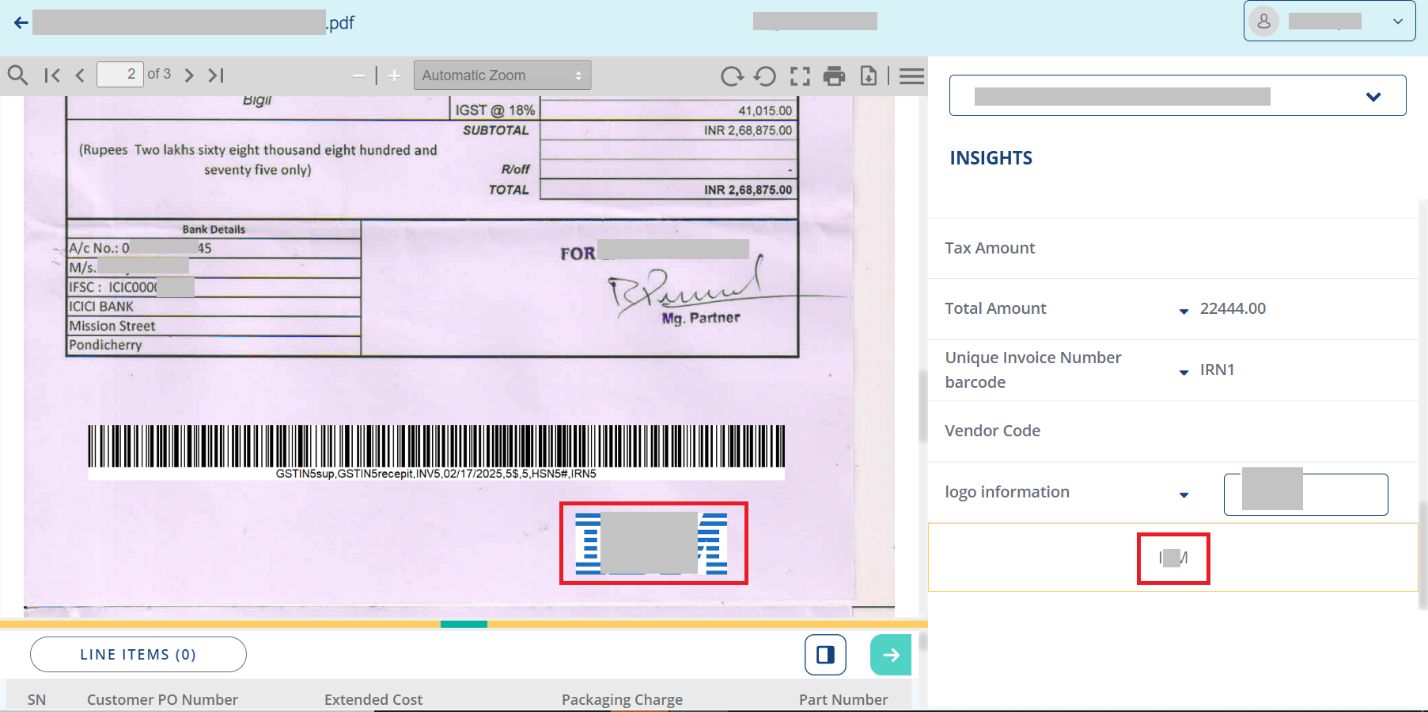
Assisted Continual Training
Adding the capability to automatically annotate the files using the base model selected in DU Trainer. After uploading the files for annotation, users can trigger “Run prediction”. This would automatically annotate the files and move them to the annotated tab. User will have the provision to further review & correct the annotations if needed.
This would significantly reduce the annotation time and also provide opportunities to fine tune the base model.
Consider a scenario, were an existing model with 15 fields needs to be extended for 2 additional fields. Users can:
-
Create a new DU trainer project with the existing model as the base model
-
Upload the files for annotation
-
Run prediction - this would automatically annotate all the files for all the 15 fields already available in the model and move them to annotated tab.
-
Review the annotations from annotated tab, make corrections if needed & add the 2 new fields
-
Run model training - A new model with all the 17 fields will be created.
-
Refer model cards for accuracy statistics
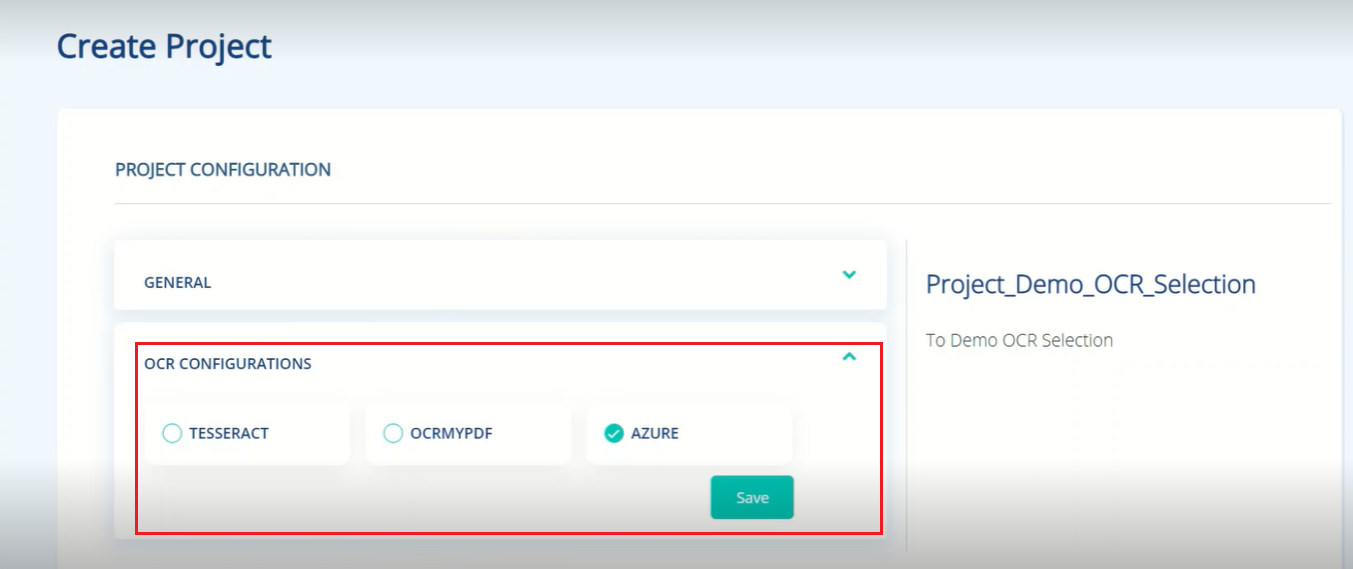
Provision to choose the OCR engine
User will have the provision to choose OCR engine while creating the training project. Model training will be based on the selected engine.
 You may choose the required model for training.
You may choose the required model for training.